How to use the models¶
Using the models¶
Directory structure: cases and runs¶
A case is a directory holding all the data needed to run the model. Multiple cases may exist next to each other in separate directories. The model will only work with one case at the time. If no case is specified when starting the model a default case (default_sbm or default_hbv) is assumed. Within a case the model output (the results) are stored in a separate directory. This directory is called the run, indicated with a runId. This structure is indicated in the figure below:
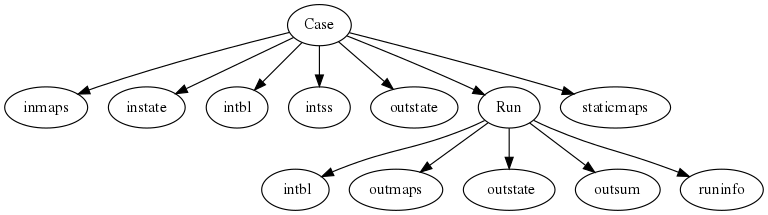
If you want to save the results and not overwrite the results from a previous run a new runId must be specified.
- inmaps
Directory holding the dynamic input data. Maps of Precipitation, potential evapotranspiration and (optionally) temperature in pcraster mapstack format.
- instate
Directory holding the input initial conditions. Can be used to hotstart the model. Alternatively the model can start with default initial conditions but in that case a long spinup procedure may be needed. This is done using the -I command-line option.
- intbl
Directory holding the lookup tables. These hold the model parameters specified per landuse/soiltype class. Note that you can use the -i option to specify an alternative name (e.g. to support an alternative model calibration). Optionally a .tbl.mult file can be given for each parameter. This file is used after loading the .tbl file or .map file to multiply the results with. Can be used for calibration etc.
- intss
Directory holding the scalar input timeseries. Scalar input data is only assumed if the ScalarInput entry in the ini file is set to 1 (True).
- outstate
Directory holding the stat variable at the end of the run. These can be copied back to the instate directory to have the model start from these conditions. These are also saves in the runId/outstate directory
- run_default
The default name for a run. if no runId is given all output data is saved in this directory.
- staticmaps
Static maps (DEM, etc) as prepared by the wflow_prep script.
- wflow_sbm|hbv.ini
The default settings file for wflow_sbm of wflow_hbv
Running the model¶
Overview¶
In general the model is run from the dos/windows/linux command line. Based on the system settings you can call the wflow_[sbm|hbv].py file directly or you need to call python with the script as the first argument e.g.:
python -m wflow.wflow_sbm -C myCase -R calib_run -T 365 -f
In the example above the wflow_sbm model is run using the information in case myCase storing the results in runId calib_run. A total to 365 timesteps is performed and the the model will overwrite existing output in the calib_run directory. The default .ini file wflow_sbm.ini located in the myCase directory is read at startup.
Command-line options¶
The command line options for wflow_sbm are summarized below, use wflow_sbm -h to view them at the command line (option for other models may be different, see their respective documentation to see the options):
wflow_sbm [-h][-v level][-L logfile][-C casename][-R runId]
[-c configfile][-T last_step][-S first_step][-s seconds]
[-P parameter multiplication][-X][-f][-I][-i tbl_dir][-x subcatchId]
[-p inputparameter multiplication][-l loglevel][--version]
-X: save state at the end of the run over the initial conditions at the start
-f: Force overwrite of existing results
-T: Set end time of the run: yyyy-mm-dd hh:mm:ss
-S: Set start time of the run: yyyy-mm-dd hh:mm:ss
-s: Set the model timesteps in seconds
-I: re-initialize the initial model conditions with default
-i: Set input table directory (default is intbl)
-x: Apply multipliers (-P/-p ) for subcatchment only (e.g. -x 1)
-C: set the name of the case (directory) to run
-R: set the name runId within the current case
-L: set the logfile
-c: name of wflow configuration file (default: Casename/wflow_sbm.ini).
-h: print usage information
-P: set parameter change string (e.g: -P "self.FC = self.FC * 1.6") for non-dynamic variables
-p: set parameter change string (e.g: -P "self.Precipitation = self.Precipitation * 1.11") for
dynamic variables
-l: loglevel (most be one of DEBUG, WARNING, ERROR)
wflow_sbm|hbv.ini file¶
The wflow_sbm|hbv.ini file holds a number of settings that determine
how the model is operated. The files consists of sections that hold
entries. A section is defined using a keyword in square brackets (e.g.
[model]). Variables can be set in each section using a
keyword = value combination (e.g. ScalarInput = 1). The default
settings for the ini file are given in the subsections below.
[model] Options for all models:
- ModelSnow = 0
Set to 1 to model snow using a simple degree day model (in that case temperature data is needed).
- WIMaxScale = 0.8
Scaling for the topographical wetness vs soil depth method.
- nrivermethod = 1
Link N values to land cover (col 1), sub-catchment (col 2) and soil type (col 3) through the N_River.tbl file. Set to 2 to link N values in N_River.tbl file to streamorder (col 1).
- MassWasting = 0
Set to 1 to transport snow downhill using the local drainage network.
- kinwaveIters = 0
Set to 1 to enable iterations of the kinematic wave (time).
- sCatch = 0
If set to another value than 0 the model will only use the specified subcatchment
- timestepsecs = 86400
timestep of the model in seconds
- Alpha = 60
Alpha term in the river width estimation function
- AnnualDischarge = 300
Average annual discharge at the outlet of the catchment for the river wiidth estimation function
- intbl = intbl
directory from which to read the lookup tables (relative to the case directory)
Specific options for wflow_hbv :
- updating = 0
Set to 1 to switch on Q updating.
- updateFile
If updating is set to 1 specify a file
- UpdMaxDist = 100
Maximum distance from the gauge used in updating for which to update the kinematic wave reservoir (in model units, metres or degree lat lon)
The options below should normally not be needed. Here you can change the location of some of the input maps.
- wflow_subcatch=staticmaps/wflow_subcatch.map
map with the subcatchments
- wflow_dem=staticmaps/wflow_dem.map
the digital elevation map
- wflow_ldd=staticmaps/wflow_ldd.map
the local drainage network
- wflow_river=staticmaps/wflow_river.map
all the cells marked as river
- wflow_riverlength=staticmaps/wflow_riverlength.map
the length of the ‘river’ in each cell
- wflow_riverlength_fact=staticmaps/wflow_riverlength_fact.map
factor to multiply the river length with
- wflow_landuse=staticmaps/wflow_landuse.map
landuse map
- wflow_soil=staticmaps/wflow_soil.map
soil map
- wflow_gauges=staticmaps/wflow_gauges.map
map with the gauge locations
- wflow_inflow=staticmaps/wflow_inflow.map
map with forced inflow points (optional)
- wflow_mgauges=staticmaps/wflow_mgauges.map
map with locations of the meteorological gauges (only needed if you use scalar timeseries as input)
- wflow_riverwidth=staticmaps/wflow_riverwidth.map
map with the width of the river
[layout]
- sizeinmetres = 0
If set to zero the cell-size is given in lat/long (the default), otherwise the size is assumed to be in metres.
[outputmaps]
Outputmaps to save per timestep. Valid options for the keys in the wflow_sbm model are all variables visible the dynamic section of the model (see the code). A few useful variables are listed below.
[outputmaps]
self.RiverRunoff=run
self.SnowMelt=sno
self.Transfer=tr
self.SatWaterDepth=swd
Tip
NB See the wflow_sbm.py code for all the available variables as this list is incomplete. Also check the framwework documentation for the [run] section
The values on the right side of the equal sign can be choosen freely.
Example content:
Self.RiverRunoff=run
self.Transfer=tr
self.SatWaterDepth=swd
[outputcsv_0-n] [outputtss_0-n]
Number of sections to define output timeseries in csv format. Each section should at lears contain one samplemap item and one or more variables to save. The samplemap is the map that determines how the timesries are averaged/sampled. All other items are variabale filename pairs. The filename is given relative to the case directory.
Example:
[outputcsv_0]
samplemap=staticmaps/wflow_subcatch.map
self.RiverRunoffMM=Qsubcatch_avg.csv
[outputcsv_1]
samplemap=staticmaps/wflow_gauges.map
self.RiverRunoffMM=Qgauge.csv
[outputtss_0]
samplemap=staticmaps/wflow_landuse.map
self.RiverRunoffMM=Qlu.tss
In the above example the river discharge of this model (self.RiverRunoffMM) is saved as an average per subcatchment, a sample at the gauge locations and as an average per landuse.
[inputmapstacks]
This section can be used to overwrite the default names of the input mapstacks
- Precipitation = /inmaps/P
timeseries for rainfall
- EvapoTranspiration = /inmaps/PET
potential evapotranspiration
- Temperature = /inmaps/TEMP
temperature time series
- Inflow = /inmaps/IF
in/outflow locations (abstractions)
Updating using measured data¶
Note
Updating is only supported in the wflow_hbv model.
If a file (in .tss format) with measured discharge is specified using the -U command-line option the model will try to update (match) the flow at the outlet to the measured discharge. In that case the -u option should also be specified to indicate which of the columns must be used. When updating is switched on the following steps are taken:
the difference at the outlet between measured and simulated Q (in mm) is determined
this difference is added to the unsaturated store for all cells
the ratio of measured Q divided by simulated Q at the outlet is used to multiply the kinematic wave store with. This ratio is scaled according to a maximum distance from the gauge.
Please note the following points when using updating:
The tss file should have as many columns as there are gauges defined in the model
The tss file should have enough data points to cover the simulation time
The -U options should be used to specify which columns to actually use and in which order to use them. For example: -u ‘[1,3,2]’ indicates to use column 1,2 and 3 in that order.
All possible options in wflow_sbm.ini file¶
[layout]
sizeinmetres = 1
[fit]
areamap = staticmaps/wflow_subcatch.map
areacode = 1
Q = testing.tss
WarmUpSteps = 1
ColMeas = 0
parameter_1 = RootingDepth
parameter_0 = M
ColSim = 0
[misc]
[outputmaps]
self.RiverRunoff = run
[framework]
debug = 0
outputformat = 1
[inputmapstacks]
Inflow = /inmaps/IF
Precipitation = /inmaps/P
Temperature = /inmaps/TEMP
EvapoTranspiration = /inmaps/PET
[model]
wflow_river = staticmaps/wflow_river.map
InterpolationMethod = inv
reinit = 1
WIMaxScale = 0.6
wflow_riverlength_fact = staticmaps/wflow_riverlength_fact.map
OverWriteInit = 0
intbl = intbl
wflow_riverwidth = staticmaps/wflow_riverwidth.map
wflow_soil = staticmaps/wflow_soil.map
sCatch = 0
Alpha = 120
wflow_subcatch = staticmaps/wflow_subcatch.map
wflow_mgauges = staticmaps/wflow_mgauges.map
timestepsecs = 86400
ScalarInput = 0
ModelSnow = 0
AnnualDischarge = 2290
wflow_landuse = staticmaps/wflow_landuse.map
TemperatureCorrectionMap = staticmaps/wflow_tempcor.map
wflow_inflow = staticmaps/wflow_inflow.map
wflow_riverlength = staticmaps/wflow_riverlength.map
wflow_ldd = staticmaps/wflow_ldd.map
wflow_gauges = staticmaps/wflow_gauges.map
wflow_dem = staticmaps/wflow_dem.map